背景
交互式分析是大数据分析的一个重要方向,基于TB甚至PB量级的数据数据为用户提供秒级甚至亚秒级的交互式分析体验,能够大大提升数据分析人员的工作效率和使用体验。限于机器的物理资源限制,对于超大规模的数据的全表扫描以及全表计算自然无法实现交互式的响应,但是在大数据分析的典型场景中,多维分析一般都会带有过滤条件,对于这种类型的查询,尤其是在高基数字段上的过滤查询,理论上可以在读取数据的时候跳过所有不相关的数据,只读取极少部分需要的数据,这种技术一般称为Data Clustering以及Data Skipping。Data Clustering是指数据按照读取时的IO粒度紧密聚集,而Data Skipping则根据过滤条件在读取时跳过不相干的数据,Data Clustering的方式以及查询中的过滤条件共同决定了Data Skipping的效果,从而影响查询的响应时间,对于TB甚至PB级别的数据,如何通过Data Clustering以及Data Skipping技术高效的跳过所有逻辑上不需要的数据,是能否实现交互式分析的体验的关键因素之一。
Data Skipping一般需要SQL引擎和存储的紧密配合,在SQL引擎中,通过类似“FilterPushDown”或者“Predicate PushDown”的执行计划优化规则把过滤条件下推到存储访问层。在存储访问层,通过文件(如HUDI,Iceberg等)或者RowGroup(如Parquet,ORC等)等级别的Min/Max/BloomFilter等信息结合过滤条件判断是否可以跳过相关文件或文件块。常用的Hive/Spark/Presto等各个SQL引擎以及HUDI/Iceberg/Parquet/ORC等存储格式均支持类似的过滤条件下推及索引技术,不过各引擎可下推的过滤条件以及各存储格式支持的索引类型不尽相同,具体的详情超过本文的讨论范围,有兴趣的可以深入研究。
本文主要基于Apache Spark以及Apache Iceberg介绍如何通过更好的Data Clustering方式实现高效的Data Skipping,从而在超大规模数据集上满足交互式的多维分析需求。
Apache Spark
Apache Spark是大数据领域最广泛使用的分布式框架之一,基本上已经成为大数据ETL和离线数据分析的标准组件。Spark提供了灵活易用的SQL/DataFrame API接口,高效的SQL Runtime执行引擎以及丰富的周边生态和工具。本文主要基于Spark进行了一些扩展,支持对数据进行一些定制化的Data Clustering,以及使用Spark SQL测试Data Skipping的效果。
Apache Iceberg
Apache Iceberg是近两年兴起的数据湖存储引擎三剑客(HUDI,Delta Lake,Iceberg)之一,Iceberg提供了表级别的抽象接口,自己在文件中维护表的元数据信息(而非通过Hive Metastore维护),基于此,Iceberg对于表的元数据管理以及表数据本身如何组织存储进行了封装,为众多SQL on Hadoop引擎向真正的分布式数仓演进提供了基础支持:
多版本的元数据管理,从而支持灵活的表的Schema变更。
粗粒度的事务支持,解决并发读写问题,并可进一步应用到近实时数仓场景。
基于文件的元数据管理,可支持超大规模数据集,避免Hive Metastore瓶颈以及分区文件的list代价。
文件级别的索引支持,在分布式任务compile阶段skip不相关文件。
Compaction/Merge支持,可以对用户透明地按照查询模式灵活调整数据文件的组织和存储方式。
本文主要使用Iceberg文件级别的Min/Max索引测试在不同Data Clustering的方式下,文件skip的效果。
SSB
SSB(Star Schema Benchmark)是TPC-H的简化版本,主要用于多维分析场景的benchmark测试,模拟电商数据分析场景,包含一个lineorder订单Fact表以及customer/supplier/part/date等4个Dimension表。本文使用了scale 100的数据集,挑选了s_city, c_city, p_brand三个字段作为过滤字段。
数据的组织方式
在大数据生态圈中,数据通常存储在HDFS分布式文件系统中,一个Hive表的数据一般会存储在对应的HDFS路径下的文件中。数据的组织指的是在向表中写入数据时如何组织数据的分布,存储方式等,使得后续的查询在访问数据时尽量高效,从而加速数据分析的效率。一个表的数据的组织形式可能会包含多种层次和方式,比如:按照一定规则将数据分布在多个子目录中;在每个目录中,将数据分布在多个文件中;在Parquet/ORC文件中,将数据分布在多个RowGroup中;将数据按照行或者列的方式组织存储;是否在全局或者局部将数据按照某种顺序组织等等。在Hive/Spark/Presto等分布式SQL引擎中,给用户提供了多种手段用于控制数据的组织方式,比如下面的几个示例:
通过分区将不同分区的数据置于不同的子目录中,从而带有分区字段过滤的查询可以直接跳过不相干的分区目录。
通过并发度或者类似hive.merge.mapredfiles之类的参数控制表中的文件数量,避免查询时访问大量小文件。
通过指定ORC/Parquet等表的存储格式,在文件中列式的组织数据,配合查询引擎在查询时跳过不相干列的数据,以及通过RowGroup级别的索引跳过不相干的RowGroup数据。
不同的数据组织方式,对于查询效率的影响是非常大的,也是数据库领域长久不衰的研究方向,限于篇幅和个人能力,本文的重点主要在于:如何在写入数据的时候,通过将数据合理的分布在不同的文件中,使得文件中查询过滤列数据的Min-Max范围尽可能的小,最好是没有交叉覆盖,从而点查询/Range过滤查询可以尽可能跳过更多的文件,加速数据分析速度。在Spark写数据任务中,一般最后一个Stage的每个Partition对应一个写出文件,所以我们通过控制最后一个Stage前的Shuffle Partitioner策略,就可以控制最终写出文件的个数以及数据如何在各个文件中分布。
测试准备
基于Scale100 SSB数据集,我们将Fact表和Dimension表关联后,打宽成一张大宽表,并发设置成1000,从而生成1000个数据文件,并将数据随机分布,对应SQL如下:
CREATE TABLE lo_iceberg USING iceberg
AS SELECT * FROM lineorder
JOIN dates ON lo_orderdate = d_datekey
JOIN customer ON lo_custkey = c_custkey
JOIN supplier ON lo_suppkey = s_suppkey
JOIN part ON lo_partkey = p_partkey
DISTRIBUTE BY random()lo_iceberg表共533363833条数据,选取s_city, c_city, p_brand三个字段作为过滤字段,验证多维分析场景下Data Skipping的效果,三个字段在表数据中的基数分别为:
| 字段 | 基数 |
|---|---|
| s_city | 5025 |
| c_city | 5025 |
| p_brand | 884686 |
测试所用SQL如下所示:
select s_city, d_year, sum(lo_revenue) as lo_revenue
from hive_catalog.ssb.lo_iceberg
where s_city='UNITED KI143'
group by s_city, d_year
order by d_year asc, lo_revenue desc;
select c_city, d_year, sum(lo_revenue) as lo_revenue
from hive_catalog.ssb.lo_iceberg
where c_city='UNITED KI158'
group by c_city, d_year
order by d_year asc, lo_revenue desc;
select p_brand, d_year, sum(lo_revenue) as lo_revenue
from hive_catalog.ssb.lo_iceberg
where p_brand='MFGR#053072348'
group by p_brand, d_year
order by d_year asc, lo_revenue desc;对于lo_iceberg表,由于数据是随机分布的,三个查询都会扫描所有的1000个数据文件。
过滤字段 扫描文件数 Data Skipping比例
s_city 1000 0%
c_city 1000 0%
p_brand 1000 0%
Linear Order
Linear Order即我们在查询中经常使用的Order By,指数据按照一个或者多个字段进行排序,在Order By后面跟着多个字段的情况下,会先按照第一个字段排序,然后在第一个字段相等时,按照第二个字段排序,依次类推。对于Iceberg表中的数据,由于数据是存储在很多个文件中,数据的排列顺序可以分为两个层面,首先是文件内部,数据是否按照一定规则排序,其次是文件之间,数据是否按照一定规则排序。比如在Spark SQL中,ORDER BY可以保证全局有序,而SORT BY只保证Partition内部有序,即在写入数据时,加上ORDER BY可以保证文件之间及文件内部数据均是有序的,而SORT BY只能保证数据文件内部数据有序,数据文件中间数据是会重复存在的。
本文只关注文件级别的Data Skipping,所以我们使用了Spark DataSet提供的repartitionByRange接口,用于实现写出数据的分区之间的数据有序性,并不保证分区数据内部的有序性,对应代码如下:
spark.read
.table("hive_catalog.ssb.lo_iceberg")
.repartitionByRange(1000, $"s_city", $"c_city", $"p_brand")
.writeTo("hive_catalog.ssb.lo_iceberg_order")
.using("iceberg")
.createLinear Order对于靠前的排序字段,Data Skipping的效果非常好,例如对于s_city,只需扫描一个文件就拿到了查询结果,但是靠后的排序字段效果就会大打折扣。在实际的测试场景中,由于第一个排序字段s_city的基数超过了文件数量,所以从第二个排序字段开始已经完全无法Skip任何文件,只能全表扫描全部的1000个文件。
repartitionByRange提供了一个基于RangePartitioner的Shuffle分区策略,首先从Source表采样数据,对采样数据排序后,按照指定分区个数,选取出对应个数的Partition Boundaries,数据在Shuffle的时候,根据Partition Boundaries判断该数据属于哪个分区,从而保证不同分区数据之间的有序性。
过滤字段 扫描文件数 Data Skipping比例
s_city 1 99.9%
c_city 1000 0%
p_brand 1000 0%
在多维分析的实际场景中,一般都会有多个常用的过滤字段,Linear Order只对靠前字段有较好的Data Skip效果,通常会采用将低基数字段作为靠前的排序字段,从而才能保证对于后面的排序字段在过滤时也有一定的Data Skipping效果,但这无法从根本上解决问题,需要引入一种新的排序机制,使得多个常用的过滤字段均能够获得比较好的Data Skipping效果。
Interleaved Order
Interleaved Order(即Z-Order)是在图像处理以及数仓中使用的一种排序方式,Z-ORDER曲线可以以一条无限长的一维曲线,穿过任意维度的所有空间,对于一条数据的多个排序字段,可以看作是数据的多个维度,多维数据本身是没有天然的顺序的,但是Z-Order通过一定规则将多维数据映射到一维数据上,构建z-value,从而可以基于一维数据进行排序,此外Z-Order的映射规则保证了按照一维数据排序后的数据同时根据多个排序字段聚集。
参考wikipedia中的Z-Order介绍,可以通过对两个数据比特位的交错填充来构建z-value,如下图所示,对于(x, y)两维数据,数据值 0 ≤ x ≤ 7, 0 ≤ y ≤ 7,构建的z-values以及z-order顺序如下: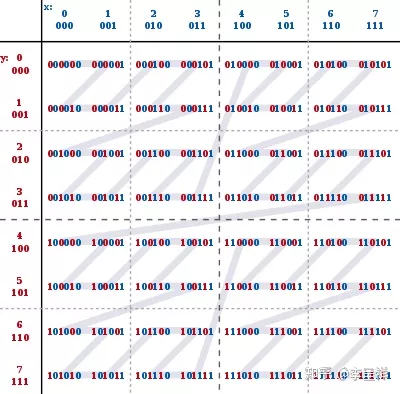
可以看到,如果根据z-values的顺序对数据进行排序,并平均分为4个文件,无论我们在查询中使用x或y字段过滤进行点查询,都可以skip一半的不相干文件,如果数据量更大,效果会更好,也就是说,基于Z-Order分区存储的文件,可以在多个字段上都有比较好的Data Skipping效果。
Interleaved Index
Z-Order实现的关键在于对z-value的映射规则,上面介绍的对于多个unsigned int递增数据,通过交叉合并比特位的方式生成z-value,由于每个维度值的比特位交叉出现在最终的z-value中,基于z-value值的排序天然的形成了一个嵌套的Z字形,对于x, y两个字段均有较好的聚集效果。不过在实际的使用场景中,基于此规则生成z-value,还需要解决如下的问题:
实际的数据类型多种多样,对于非unsigned int类型的数据如何处理。
每个维度值的比特位不同如何处理,例如一个short类型和一个int类型如何交叉合并比特位。
交叉合并的z-value比特位是各个维度值比特位之和,合并后的比特位如果超过64(即一个Long类型的比特位),如何在开发语言中存储和表达z-value的值并进行比较。
问题2和3相对来说比较好处理,对于问题1,AWS DynamoDB[4]的相关文章里给出了一些解决方案,这里稍作解释。unsigned int类型的比特位字典序和数字本身的顺序是一致的,例如1<2, 其比特位也同样如此001<010,所以其比特位交叉合并结果可以形成Z-Order,对于其他的数据类型,同样要保证其比特位字典序和数据本身的顺序是一致的。以Int类型为例,在计算机中普遍是采用补码的方式来表示符号位,比特位第一位用于表示符号位,如下所示:
数值 比特位
0 0000 0000
1 0000 0001
2 0000 0010
126 0111 1110
127 0111 1111
-128 1000 0000
-127 1000 0001
1000 0010
-2 1111 1110
-1 1111 1111
该类型数据的比特位字典序和数值本身的顺序并不一致,需要进行转化,一个简单的做法是将第一位比特位进行逆转,使用逆转后的结果参与z-value值的计算,如下所示:
数值 比特位 首位反转 结果值
0 0000 0000 1000 0000 128
1 0000 0001 1000 0001 129
2 0000 0010 1000 0010 130
126 0111 1110 1111 1110 254
127 0111 1111 1111 1111 255
-128 1000 0000 0000 0000 0
-127 1000 0001 0000 0001 1
-126 1000 0010 0000 0010 2
-2 1111 1110 0111 1110 126
-1 1111 1111 0111 1111 127
对于Float/Double/String/Date/Timestamp等各种类型的值都需要进行特定的转换,基本思路均是将对应类型数据在保证数值顺序的基础上映射成无符号数值类型参与z-value的计算。这种方式虽然可行,但是也会有缺陷,例如对于String类型,由于是变长类型,只能选取固定长度字符,使用其ASCII码的编号值参与z-value的计算,对于url字段,选取前6位字符可能结果全部是“http:/”,导致该字段完全没有区分度,起不到任何Data Skipping的效果。
对于这种保序转换更普遍的一个问题是:很难找到一个合适的转换方式使得其他类型的数据可以保序的映射成从0开始的无符号整型数,原因有两个:
映射方式的原因,比如String类型,选取前4位字符映射成无符号长整型,每个字符对应Long的8个比特位,无法映射成从0开始的递增长整型。
数据本身的原因,比如Int类型数据,其数值从业务定义上就是从1000000开始。
Interleaving Index基于比特位交叉填充,如果所有维度数据都是从0开始的递增正整数,计算结果z-value会按照Z-ORDER曲线有序,但是如果参与计算的维度数据不是从0开始的递增数据集的话,实际上计算出来的z-values只是完整Z-ORDER曲线中的部分点,而这部分点本身并不一定是Z字形分布的,特别是在不同维度值比特位没有交集的情况下,例如x取值是[0, 1, 2, 3, 4, 5, 6, 7], y取值是[8, 16, 24, 32, 40, 48, 56, 64], 计算出来的z-value排序结果实际上和数据按照Order By y, x排序的效果是一样的,这就使得在实际的使用场景中,使用Z-Order让数据按照多个字段聚集的效果很可能没有很好的按照多个字段聚集。
Boundary-based Interleaved Index
为了解决Interleaving Index在实际数据场景中的问题,一个最简单的思路就是针对参与z-value计算的过滤字段取Distinct值进行排序,排序的序号值自然就是从0开始的连续正整数,且和数据本身的顺序保持一致,但是这种做法的计算代价太大了,对于所有参与Z-ORDER字段需要全局排序,构建字典,在Shuffle时基于字典获取映射值参与z-value计算,会严重影响数据写入的速度,在实际场景中并不可行。
我们在测试中实现了一种基于Boundary构建Interleaved Index的方法,在开始阶段,对数据进行采样,从采样的数据中,对每个参与Z-ORDER的字段筛选规定个数的Boundaries并进行排序,每个字段映射为该数据在Boundaries中的Index,然后参与z-value的计算。由于Boundaries的index一定是从0开始的连续正整型数据,完全满足interleaving index的计算需求。
通过Boundary-based Interleaved Index,我们基于Spark实现了一个Z-Order Ordering实现,并重用RangePartitioner对数据进行分区,写入的逻辑如下:
spark.read
.table("hive_catalog.ssb.lo_iceberg")
.repartitionByZOrderRange(1000, $"s_city", $"c_city", $"p_brand")
.writeTo("hive_catalog.ssb.lo_iceberg_zorder")
.using("iceberg")
.create使用同样的SQL查询后,通过Metric信息拿到扫描文件数量如下:
过滤字段 扫描文件数 Data Skipping比例
s_city 186 81.4%
c_city 164 83.6%
p_brand 135 86.5%
相比于Linear Order,经过Z-Order Clustering的数据,在s_city字段上的Data Skipping比例稍有下降,但是在c_city以及p_brand字段上的Data Skipping比例大大增加,在实际的测试场景中,可能有10倍甚至100倍以上的性能提升。
在目前的公开资料中,Databricks Runtime提供了ZOrder BY的支持[2],但是未提供任何实现细节。AWS DynamoDB实现了Z-Order Index,并在公开文章[3, 4]中介绍了实现思路,使用了上面“Interleaved Index”一节介绍的方式。在开源的大数据生态组件中,目前Hive/Spark/Presto都还没有官方的Z-Order支持,Impala在4.0版本中提供了对ZORDER BY的支持,也使用了类似上面“Interleaved Index”一节介绍的方式进行数据转换,但不是计算z-value,而是实现了一个特殊的Comparator用于顺序比较。
Hilbert Curve Order
Interleaved Order可以按照多个字段分布聚集,但是Z-ORDER曲线也有一个比较小的缺点,就是Z字形之间的连接可能跨度会比较长,在Spark的实现中我们基于Ranger Partitioner切分不同分区数据,切分的Boundary没法准确切中完整的Z字形区域数据,所以IceBerg文件中的Min/Max可能会出现较大的重合,降低Data Skipping的效率。Hibert Curve是另外一种可以用一条无限长的线,穿过任意维度空间里面的所有点的曲线类型[5],并且相对于Z-ORDER曲线,Hibert曲线在其将多维空间转换为一维空间的方法更好地保留了空间邻近性。一到六阶Hibert曲线的示例如下: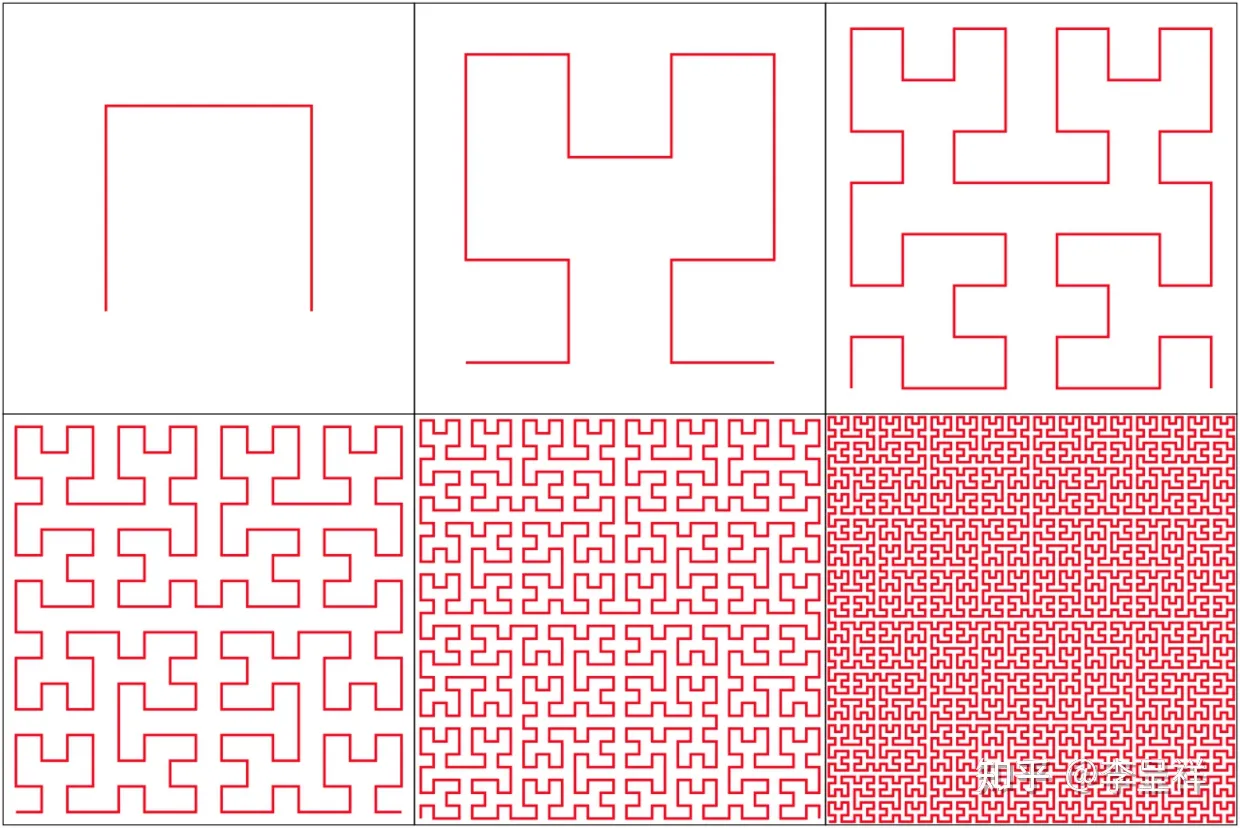
可以看到,相比于Z-ORDER曲线,Hibert曲线节点间的临近性更好,没有Z-ORDER曲线中大幅跨空间连接线的存在,这就使得无论我们如何对Hibert曲线进行切分,每个分区对应文件的Min/Max值重合范围都会比较少。
对于Hibert曲线,我们在测试中同样采用了类似Boundary-based Interleaved Index的方式计算hibert-value,首先对数据进行采样,针对每个参与计算的字段选取合适数量的boundaries并排序,使用字段值在boundaries中的index值参与hibert-value的计算。
通过Boundary-based Hibert Index,我们基于Spark实现了一个Hibert Curve Ordering实现,并重用RangePartitioner对数据进行分区,写入的逻辑如下:
spark.read
.table("hive_catalog.ssb.lo_iceberg")
.repartitionByHibertRange(1000, $"s_city", $"c_city", $"p_brand")
.writeTo("hive_catalog.ssb.lo_iceberg_hibert")
.using("iceberg")
.create使用同样的SQL查询后,通过Metric信息拿到扫描文件数量如下:
过滤字段 扫描文件数 Data Skipping比例
s_city 145 85.5%
c_city 131 86.9%
p_brand 117 88.3%
相比于Z-Order,经过Hibert Curve Clustering的数据,在三个过滤字段上的Data Skipping比例均有进一步的提升。
展望
通过Z-Order和Hibert Curve Order,可以让数据按照多个字段聚集存储,但是在实际的分析场景中,多个过滤字段出现的概率并不相同,如果可以按照过滤字段出现的权重,决定该字段数据聚集的程度,自然可以进一步的提升实际场景中的Data Skipping的效率。随着机器学习/深度学习的发展,在学术领域也有越来越多通过机器学习/深度学习的方法找到更合适的Data-Clustering的研究[7],我们后续也会在这个方向进行一定的探索。
此外,基于对于Z-Order/Hibert Curve Order等更多Data Clustering方式的支持,我们可以通过收集用户的查询Query,自动/手动的选择合适的Data Clustering方式,结合Iceberg提供的事务支持,透明地对数据进行合理的重新组织,在用户无需感知的情况下,大大加速用户的数据分析速度。
总结
本文主要介绍了我们在大数据Data Clustering和Data Skipping的一些探索,我们实现了一个基于Z-ORDER进行Range Partition的Data Clustering策略,使得数据可以按照Z-ORDER顺序写入到不同的数据文件中。提出了一个新的Boundary-based Interleaved Index的计算方法用于计算z-value,可以支持所有的数据类型,并保证Z-ORDER排序不受数据值本身的分布影响,在实际的测试中,在多个过滤字段上都取得了比较好的Data Skipping效果。更进一步,我们实现了一个基于Hibert Curve Order的Data Clustering策略,相对于Z-ORDER,可以进一步减少分区文件Min/Max重合范围,提升Data-Skipping的效率。
B站数据平台OLAP部门负责支持公司业务的交互式分析需求,我们在持续探索如何在超大规模数据集上进行交互式分析的技术方向,如果你也对这个方向感兴趣,欢迎加入我们或者联系我们技术交流,联系方式:lichengxiang@bilibili.com.
参考
https://en.wikipedia.org/wiki/Z-order_curve
https://databricks.com/blog/2018/07/31/processing-petabytes-of-data-in-seconds-with-databricks-delta.html
https://aws.amazon.com/cn/blogs/database/z-order-indexing-for-multifaceted-queries-in-amazon-dynamodb-part-1/
https://aws.amazon.com/cn/blogs/database/z-order-indexing-for-multifaceted-queries-in-amazon-dynamodb-part-2/
https://en.wikipedia.org/wiki/Hilbert_curve
https://issues.apache.org/jira/browse/IMPALA-8755
https://arxiv.org/abs/1912.0166
没有评论