我们都知道 Spark 能够有效的利用内存并进行分布式计算,其内存管理模块在整个系统中扮演着非常重要的角色。为了更好地利用 Spark,深入地理解其内存管理模型具有非常重要的意义,这有助于我们对 Spark 进行更好的调优;在出现各种内存问题时,能够摸清头脑,找到哪块内存区域出现问题。
首先我们知道在执行 Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程,前者为主控进程,负责创建 Spark 上下文,提交 Spark 作业(Job),并将作业转化为计算任务(Task),在各个 Executor 进程间协调任务的调度,后者负责在工作节点上执行具体的计算任务,并将结果返回给 Driver,同时为需要持久化的 RDD 提供存储功能。由于 Driver 的内存管理相对来说较为简单,本文主要对 Executor 的内存管理进行分析,下文中的 Spark 内存均特指 Executor 的内存。
另外,Spark 1.6 之前使用的是静态内存管理 (StaticMemoryManager) 机制,
StaticMemoryManager 也是 Spark 1.6 之前唯一的内存管理器。在 Spark1.6 之后引入了统一内存管理
(UnifiedMemoryManager) 机制,UnifiedMemoryManager 是 Spark 1.6 之后默认的内存管理器,1.6 之前采用的静态管理(StaticMemoryManager)方式仍被保留,可通过配置 spark.memory.useLegacyMode 参数启用。
这里仅对统一内存管理模块 (UnifiedMemoryManager) 机制进行分析。
一、Executor内存总体布局
默认情况下,Executor不开启堆外内存,因此整个 Executor 端内存布局如下图所示: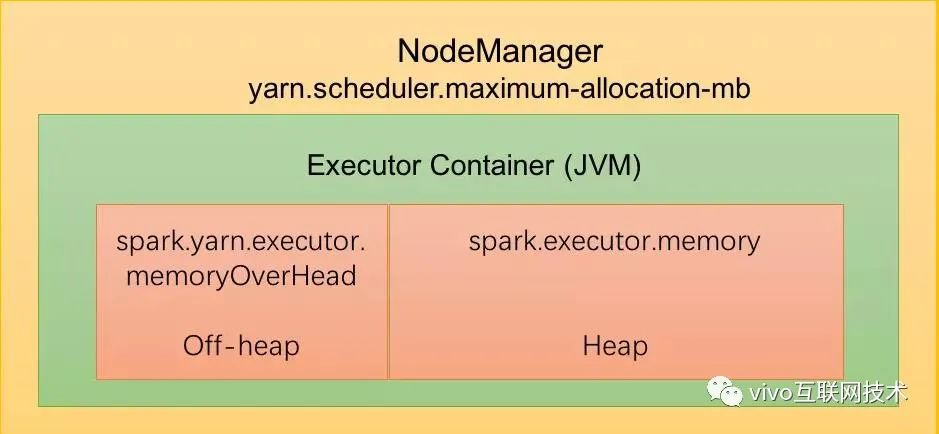
没有评论