set hive.mapred.mode=nonstrict;
set hive.auto.convert.join=true;
set hive.merge.orcfile.stripe.level=false;
set hive.exec.max.created.files=1000000;
set hive.map.aggr=true;
set hive.groupby.skewindata=true;
1. Map输入合并小文件
set mapred.max.split.size=1024000000; #每个Map最大输入大小
set mapred.min.split.size.per.node=256000000;#一个节点上split的至少的大小
set mapred.min.split.size.per.rack=256000000;#一个交换机下split的至少的大小
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; #执行Map前进行小文件合并在开启了org.apache.hadoop.hive.ql.io.CombineHiveInputFormat后,一个data node节点上多个小文件会进行合并,合并文件数由mapred.max.split.size限制的大小决定。
mapred.min.split.size.per.node决定了多个data node上的文件是否需要合并~
mapred.min.split.size.per.rack决定了多个交换机上的文件是否需要合并~
2.输出合并
set hive.merge.mapfiles=true; #在Map-only的任务结束时合并小文件
set hive.merge.mapredfiles=true; #在Map-Reduce的任务结束时合并小文件
set hive.merge.size.per.task = 256*1000*1000; #合并文件的大小
set hive.merge.smallfiles.avgsize=975175680; #当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge3.JVM重利用
set mapred.job.reuse.jvm.num.tasks=20;4. group by 优化
hive.groupby.skewindata=true; #如果group by过程出现倾斜应该设置为true
set hive.groupby.mapaggr.checkinterval=100000; #这个是group的键对应的记录条数超过这个值则会进行优化5. job 并行 优化
6.解决数据倾斜
1.什么是数据倾斜?
hadoop框架的特性决定最怕数据倾斜。
由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点。
症状:
map阶段快,reduce阶段非常慢;
某些map很快,某些map很慢;
某些reduce很快,某些reduce奇慢。
如下情况:
A、数据在节点上分布不均匀(无法避免)。
B、join 时 on 关键词中个别值量很大(如null值)
C、count(distinct),数据量大的情况下,容易数据倾斜,
因为count(distinct)是按group by字段分组,按distinct字段排序。(有时无法避免)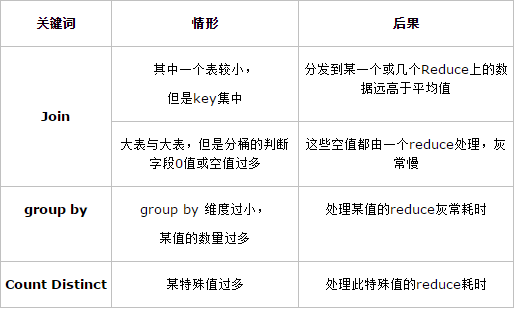 https://img-blog.csdn.net/2015050410295277
https://img-blog.csdn.net/2015050410295277
2.数据倾斜的解决方案
1.参数调节
hive.map.aggr=true
Map 端部分聚合,相当于Combiner
hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定为true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
2.sql语句调节
Join:
关于驱动表的选取:选用join key分布最均匀的表作为驱动表
做好列裁剪和filter操作,以达到两表做join的时候,数据量相对变小的效果。
大表与小表Join
使用map join让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce。
大表与大表Join:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
count distinct大量相同特殊值:
count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
group by维度过小:
采用sum() 与group by的方式来替换count(distinct)完成计算。
特殊情况特殊处理:
在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理,最后union回去。
3.应用场景
1.空置产生的数据倾斜
解决方法1: user_id为空的不参与关联
解决方法2 :赋与空值新的key值
2.不同数据类型关联产生数据倾斜
如int和string类型关联 ---解决方法:把数字类型转换成字符串类型 on a.usr_id = cast(b.user_id as string);
3.小表不小不大,怎么用 map join 解决倾斜问题
users 表有 600w+ 的记录,把 users 分发到所有的 map 上也是个不小的开销,而且 map join 不支持这么大的小表。如果用普通的 join,又会碰到数据倾斜的问题。
解决方法:
select /*+mapjoin(x)*/* from log a
left outer join (
select /*+mapjoin(c)*/d.*
from ( select distinct user_id from log ) c
join users d
on c.user_id = d.user_id
) x
on a.user_id = b.user_id;
没有评论