
ApacheFlink®是一款分布式、高可用、持久可用、准确的开源流式处理框架。
对无边界数据集的连续处理
1.两种数据集类型
- 无边界:连续追加的无限数据集
- 有界:不变的有限数据集
2.两种执行模式
- 流式处理:数据源源不断的生成,并处理
- 批处理:在有限的时间内执行处理并运行完成,完成后释放计算资源
Flink特点
- 提供准确的结果,甚至在出现无序或者延迟加载的数据的情况下
- 具有状态化的容错功能,可以在保持一次应用程序状态的同时无缝地从故障中恢复
- 大规模执行,在数千个节点上运行,具有非常好的吞吐量和延迟特性
下面列出的许多Flink功能 - 状态管理,无序数据的处理,灵活的窗口 - 对于在无界数据集上计算精确的结果非常重要,并且由Flink的流式执行模型来实现。
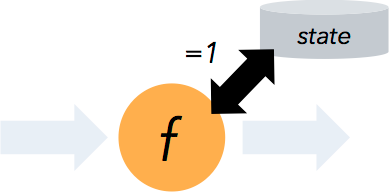
- Flink 确保为有状态计算仅有一次语义。‘有状态’的意思是flink可以维护一个已经处理过的数据的集合或者汇总。Flink的检查点机制确保了在发生故障时,应用程序状态的精确语义。
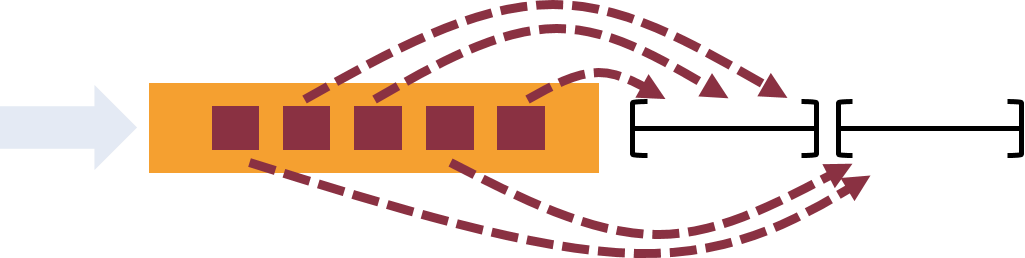
- Flink支持流处理和事件时间窗口的语义。事件时间可以轻松计算事件到达顺序不正确,事件可能延迟到达的流的精确结果
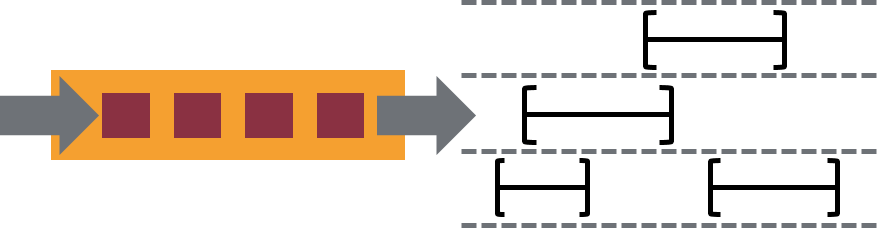
- 除了数据驱动的窗口,Flink还支持基于时间、计数或会话的灵活窗口。窗口可以通过灵活的触发条件进行定制,以支持复杂的流模式。Flink的窗口可以模拟数据被创建的真实环境。
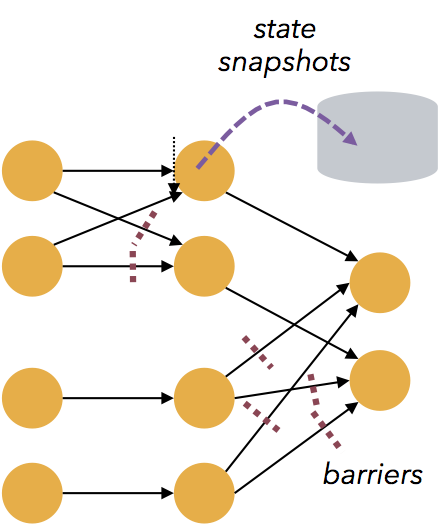
- Flink的容错功能是轻量级的。在既能让系统保持高吞吐率的情况下,同事提供仅一次一致性的保证。Flink从零数据丢失的故障恢复,而可靠性和延迟之间的折衷可以忽略不计。
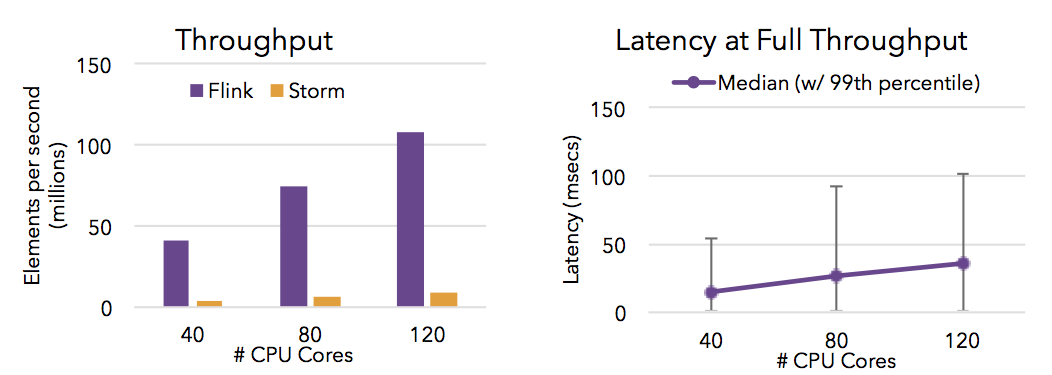
- Flink能够提供高吞吐量和低延迟(快速处理大量数据)。下面的图表显示了Apache Flink和Apache Storm的性能,完成了需要流式数据混洗的分布式项目计数任务
- Flink的保存点提供了一个状态版本管理机制,可以更新应用程序或重新处理历史数据,而且不会丢失状态,停机时间最短
- Flink设计用于在数千个节点的大型集群上运行,除了独立集群模式之外,Flink还提供对YARN和Mesos的支持
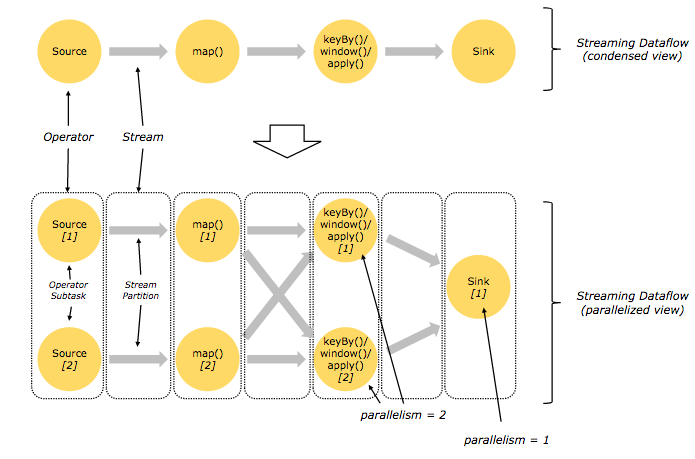
flink的架构
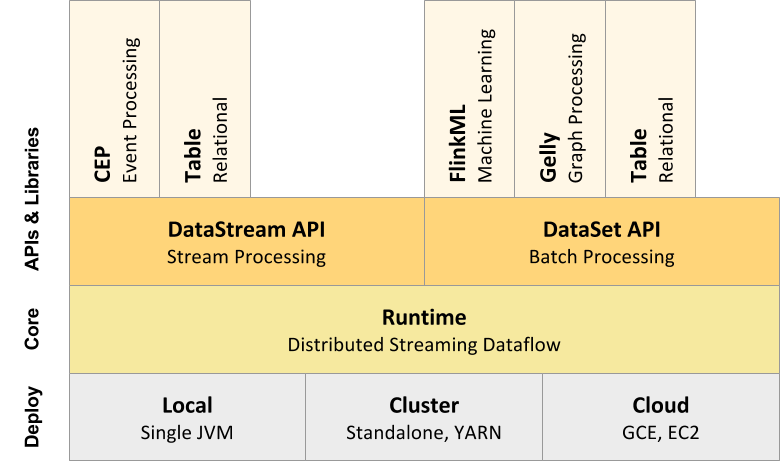
APIs
- Flink的DataStream API适用于实现数据流转换的程序(例如过滤,更新状态,定义窗口,聚合)。
- DataSet API是用于实现上的数据集的变换(例如,滤波,映射,连接,分组)的程序。
- Table API 为关系数据流和批量处理类似于SQL的表达式语言可容易地嵌入在弗林克的数据集和的数据流中的API(爪哇和Scala)。
- Streaming SQL 使SQL查询能够在流式处理和批处理表上执行。语法基于Apache Calcite™。
没有评论