hadoop内存的配置,涉及到两个方面:
- namenode/datanode/resourcemanager/nodemanager的HEAPSIZE环境变量
- 在配置文件/Configuration中影响MR运行的变量
HEAPSIZE环境变量
hadoop-env.sh此配置文件 hdfs和yarn脚本都会加载。hdfs是使用HADOOP_HEAPSIZE,而yarn使用新的环境变量YARN_HEAPSIZE。
hadoop/hdfs/yarn命令最终会把HEAPSIZE的参数转换了 JAVA_HEAP_MAX,把它作为启动参数传递给Java
- hadoop
hadoop命令是把 HADOOP_HEAPSIZE 转换为 JAVA_HEAP_MAX ,调用路径:
hadoop -> hadoop-config.sh -> hadoop-env.shJAVA_HEAP_MAX=-Xmx1000m
# check envvars which might override default args
if [ "$HADOOP_HEAPSIZE" != "" ]; then
#echo "run with heapsize $HADOOP_HEAPSIZE"
JAVA_HEAP_MAX="-Xmx""$HADOOP_HEAPSIZE""m"
#echo $JAVA_HEAP_MAX
fi- hdfs
hdfs其实就是从hadoop脚本里面分离出来的。调用路径:
hdfs -> hdfs-config.sh -> hadoop-config.sh -> hadoop-env.sh- yarn
yarn也调用了hadoop-env.sh,但是设置内存的参数变成了 YARN_HEAPSIZE 。调用路径:
yarn -> yarn-config.sh -> hadoop-config.sh -> hadoop-env.shJAVA_HEAP_MAX=-Xmx1000m
# For setting YARN specific HEAP sizes please use this
# Parameter and set appropriately
# YARN_HEAPSIZE=1000
# check envvars which might override default args
if [ "$YARN_HEAPSIZE" != "" ]; then
JAVA_HEAP_MAX="-Xmx""$YARN_HEAPSIZE""m"
fi- 实例:
配置hadoop参数的时刻,一般都是配置 hadoop-env.sh 如:export HADOOP_HEAPSIZE=16000 查看相关进程命令有:
/usr/local/jdk1.7.0_17/bin/java -Dproc_resourcemanager -Xmx1000m
/usr/local/jdk1.7.0_17/bin/java -Dproc_timelineserver -Xmx1000m
/usr/local/jdk1.7.0_17/bin/java -Dproc_nodemanager -Xmx1000m
/usr/local/jdk1.7.0_17/bin/java -Dproc_journalnode -Xmx16000m
/usr/local/jdk1.7.0_17/bin/java -Dproc_namenode -Xmx16000m
/usr/local/jdk1.7.0_17/bin/java -Dproc_journalnode -Xmx16000m
/usr/local/jdk1.7.0_17/bin/java -Dproc_datanode -Xmx16000m与hdfs有关的内存都修改成功了。而与yarn的还是默认的1g(堆)内存。
MR配置文件参数
分成两组,一种是直接设置数字(mb结束的属性),一种是配置java虚拟机变量的-Xmx
* yarn.app.mapreduce.am.resource.mb、mapreduce.map.memory.mb、mapreduce.reduce.memory.mb
用于调度计算内存,是不是还能分配任务(计算额度)
* yarn.app.mapreduce.am.command-opts、mapreduce.map.java.opts、mapreduce.reduce.java.opts
程序实际启动使用的参数一个是控制中枢,一个是实实在在的限制。
- 下面用实践来验证效果:
先搞一个很大大只有一个block的文件,把程序运行时间拖长一点
修改opts参数,查看效果
修改mb参数,查看效果 - 实践一
mapreduce.map.memory.mb设置为1000,而mapreduce.map.java.opts设置为1200m。程序照样跑的很欢!!
同时从map的 YarnChild 进程看出起实际作用的是 mapreduce.map.java.opts 参数。memory.mb用来计算节点是否有足够的内存来跑任务,以及用来计算整个集群的可用内存等。而java.opts则是用来限制真正任务的堆内存用量。
注意 : 这里仅仅是用来测试,正式环境java.opts的内存应该小于memory.mb!!具体配置参考:yarn-memory-and-cpu-configuration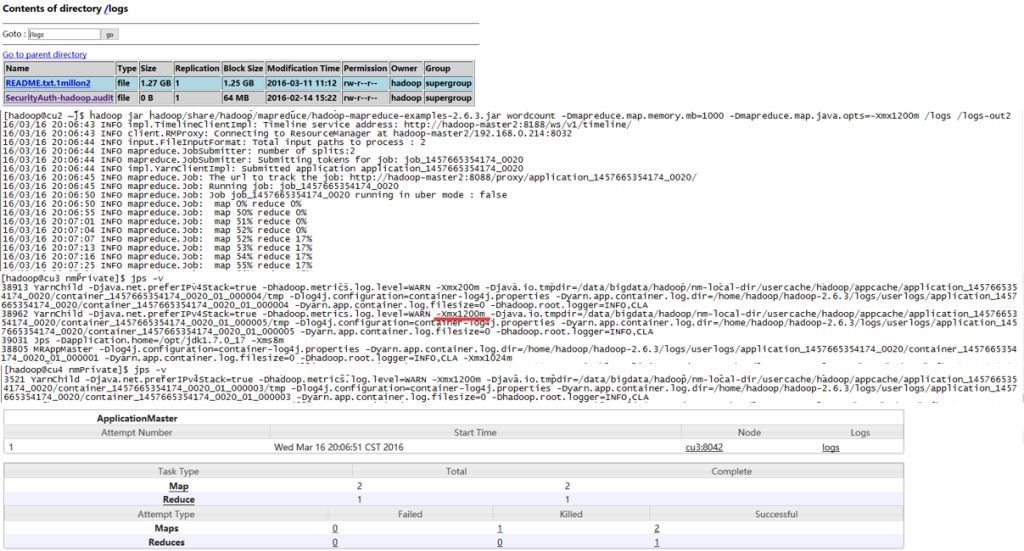
- 实践二
map.memory.mb设置太大,导致调度失败!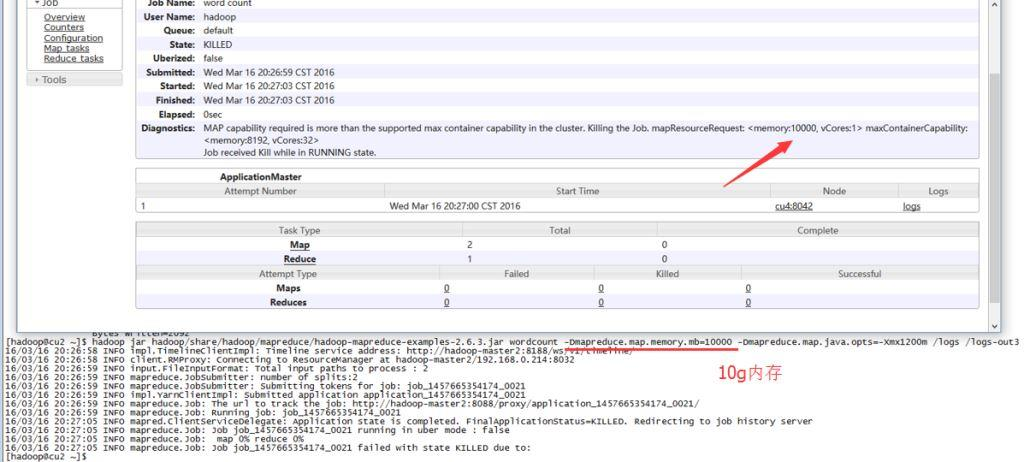
- 实践三
尽管实际才用不大于1.2G的内存,但是由于mapreduce.map.memory.mb设置为8G,整个集群显示已用内存18G(2 8g + 1 2g)。登录实际运行任务的机器,实际内存其实不多。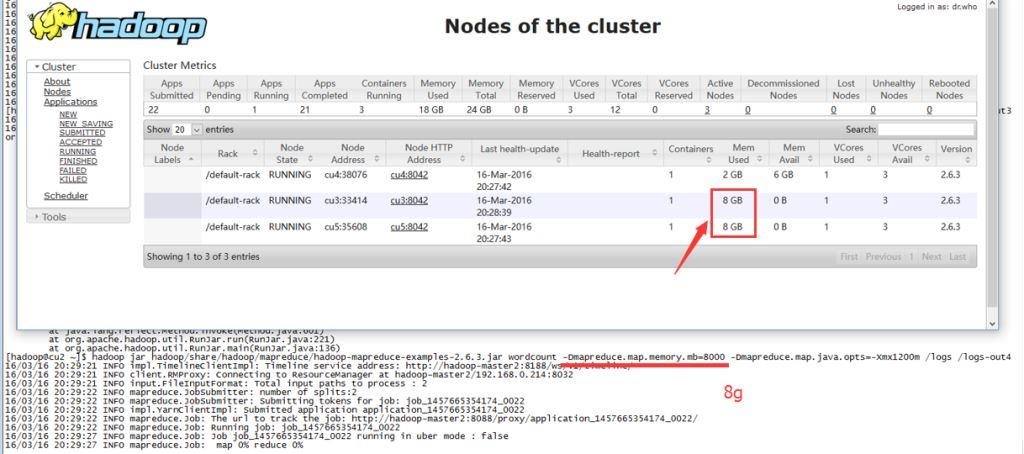
reduce和am(appmaster)的参数类似。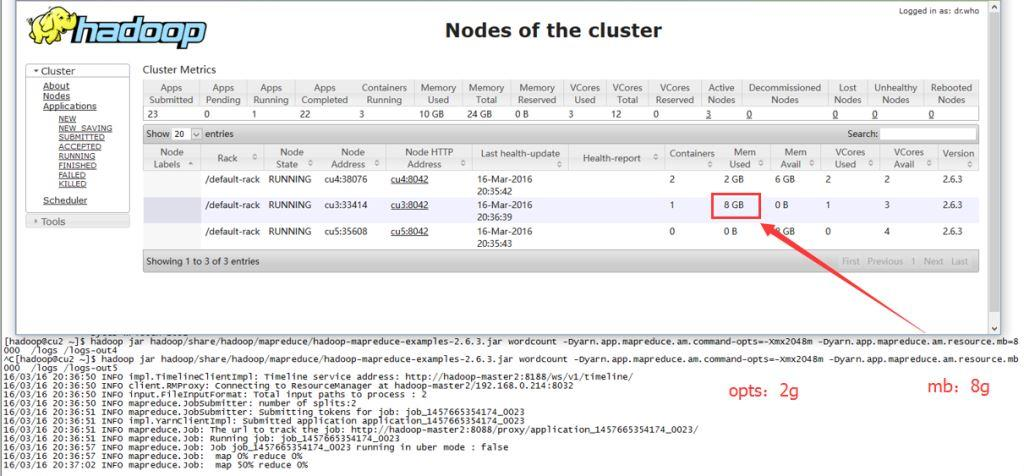
mapred.child.java.opts参数
这是一个过时的属性,当然你设置也能起效果(没有设置mapreduce.map.java.opts/mapreduce.reduce.java.opts)。相当于把MR的java.opts都设置了。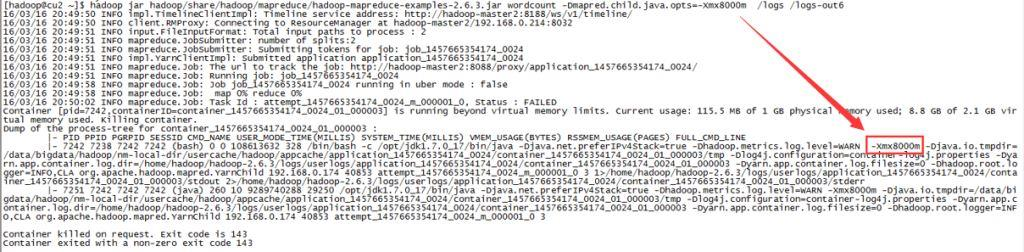
获取map/reduce的opts中间会取 mapred.child.java.opts 的值。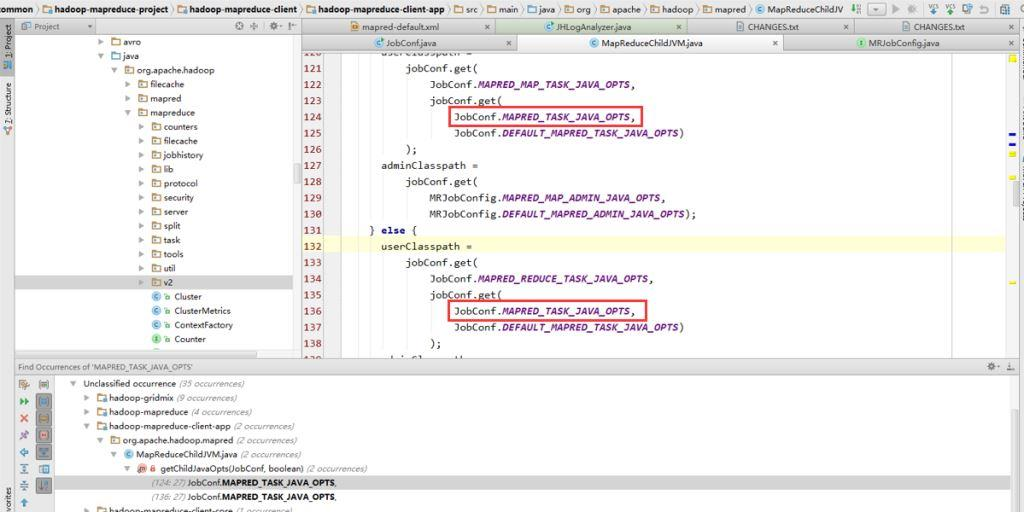
admin-opts
查找源码后,其实opts被分成两部分:admin和user。admin的写在前面,user在后面。admin设置的opts可以覆盖user设置的。应该是方便用于设置默认值吧
实例
同时在一台很牛掰的机器上跑程序(分了yarn.nodemanager.resource.memory-mb 26G内存),但是总是只能一次跑一个任务,但还剩很多内存(20G)没有用啊!!初步怀疑是调度算法的问题。
查看了调度的日志,初始化的时刻会输出 scheduler.capacity.LeafQueue 的日志,打印了集群控制的一些参数。然后 同时找到一篇http://stackoverflow.com/questions/33465300/why-does-yarn-job-not-transition-to-running-state 说是调整 yarn.scheduler.capacity.maximum-am-resource-percent ,是用于控制appmaster最多可用的资源。
appmaster的默认内存是: yarn.app.mapreduce.am.resource.mb 1536(client设置有效), yarn.scheduler.capacity.maximum-am-resource-percent 0.1。
跑第二job的时刻,第二个appmaster调度的时刻没有足够的内存(26G * 0.1 - 1.536 < 1.536),所以就跑不了两个job。
CLIENT_OPTS
一般 HADOOP 集群都会配套 HIVE,hive直接用 sql 来查询数据比mapreduce简单很多。启动hive是直接用 hadoop jar 来启动的。相对于一个客户端程序。控制hive内存的就是 HADOOP_CLIENT_OPTS 环境变量中的 -Xmx 。
所以要调整 hive 内存的使用,可以通过调整 HADOOP_CLIENT_OPTS 来控制。(当然理解这些环境变量,你就可以随心随欲的改)
[hadoop@cu2 hive]$ sh -x bin/hiveserver2
...
++ exec /home/hadoop/hadoop/bin/hadoop jar /home/hadoop/hive/lib/hive-service-1.2.1.jar org.apache.hive.service.server.HiveServer2
[hadoop@cu2 hive]$ grep -3 "HADOOP_CLIENT_OPTS" ~/hadoop/etc/hadoop/hadoop-env.sh
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="-Xmx128m $HADOOP_CLIENT_OPTS"
#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
# On secure datanodes, user to run the datanode as after dropping privileges.
[hadoop@cu2 hive]$ jinfo 10249
...
VM Flags:
-Xmx256m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/home/hadoop/hadoop-2.6.3/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/home/hadoop/hadoop-2.6.3 -Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,console -Djava.library.path=/home/hadoop/hadoop-2.6.3/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Xmx128m -Dhadoop.security.logger=INFO,NullAppender
[hadoop@cu2 hive]$ jmap -heap 10249
...
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 134217728 (128.0MB)
...
没有评论