Journal Node作用
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
原理图和过程
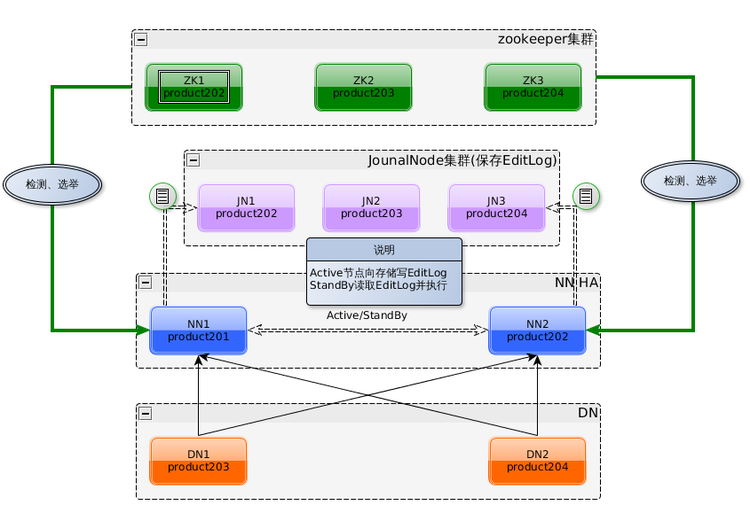
A:NN1、NN2(或者更多个NN节点)只有一个是Active状态,通过自带ZKFailoverController组件(zookeeper客户端)和zookeeper集群协同对所有NN节点进行检测和选举来达到此目的。
B:Active NN 的EditLog 写入共享的JournalNode集群中,Standby NN通过JournalNode集群获取Editlog,并在本地运行来保持和Active NN 的元数据同步。
C:如果不配置zookeeper,可以手工切换Active NN/Standby NN;如果要配置zookeeper自动切换,还需要提供切换方法,也就是要配置dfs.ha.fencing.methods参数。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了
hadoop如何配置高可用HA
http://eksliang.iteye.com/blog/2226986
JournalNode服务器:运行的JournalNode进程非常轻量,可以部署在其他的服务器上。注意:必须允许至少3个节点。当然可以运行更多,但是必须是奇数个,如3、5、7、9个等等。当运行N个节点时,系统可以容忍至少(N-1)/2(N至少为3)个节点失败而不影响正常运行。
实现分析
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/
没有评论